最近发现Gustavo Duarte的blog上Best of系列的文章,其内容大多涉及linux内核管理和虚拟内存,但是又能以浅显易容的方式展现出来,因此我想把它们翻译出来,跟大家分享。
没有按照原blog上的顺序,读了哪篇就翻译哪篇。今天翻译
How The Kernel Manages Your Memory.
为了大家便于理解,我在这里贴出原文内容,采用一段英文一段中文的方式来翻译。
After examining the virtual address layout of a process, we turn to the kernel and its mechanisms for managing user memory. Here is gonzo again:
在学习完进程的虚拟空间布局后,我们转过来看看内核和进程内存管理的机制。这里仍然以gonzo为例:
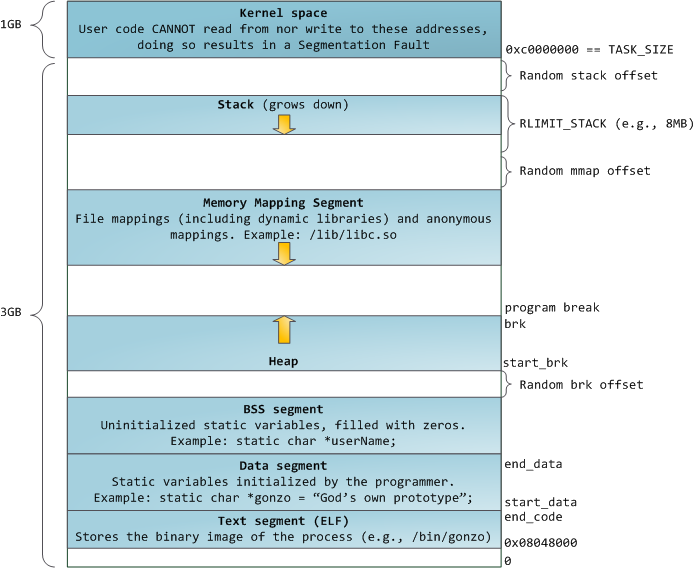
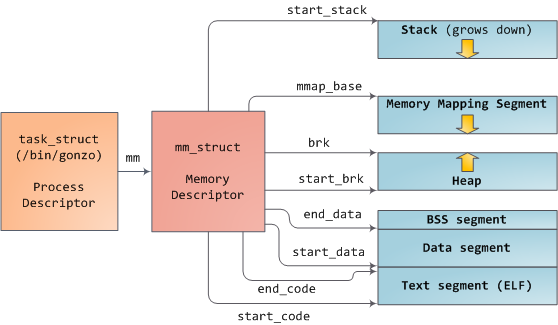
Linux processes are implemented in the kernel as instances of task_struct, the process descriptor. The mm field in task_struct points to the memory descriptor, mm_struct, which is an executive summary of a program’s memory. It stores the start and end of memory segments as shown above, the number of physical memory pages used by the process (rss stands for Resident Set Size), the amount of virtual address space used, and other tidbits. Within the memory descriptor we also find the two work horses for managing program memory: the set of virtual memory areas and the page tables. Gonzo’s memory areas are shown below:
内核把进程表示为 task_struct 结构体的实例,即进程描述符。其mm字段指向一个 mm_struct 结构体,即存储描述符,它描述了进程使用内存的一个概况。如上图所示。下图显示了Gonzo进程的内存区域:
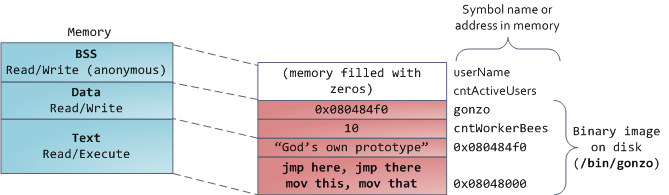
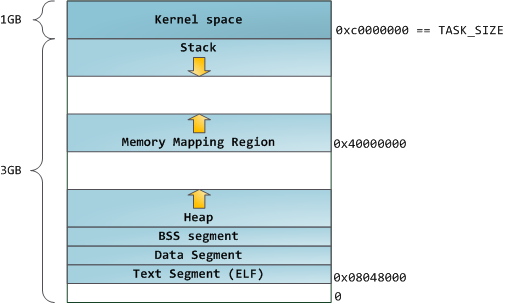
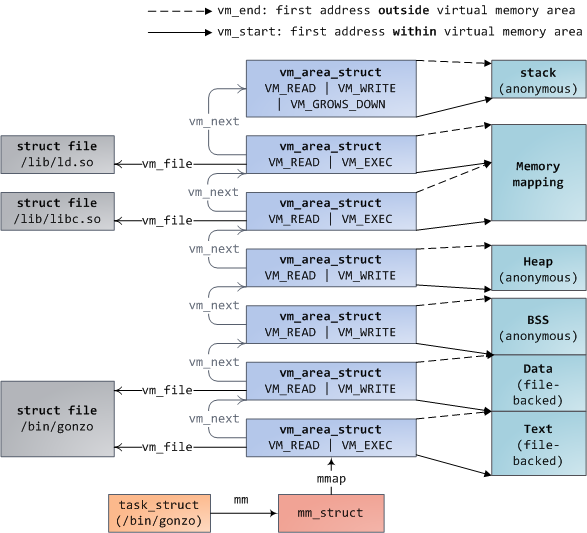
Each virtual memory area (VMA) is a contiguous range of virtual addresses; these areas never overlap. An instance of vm_area_struct fully describes a memory area, including its start and end addresses, flags to determine access rights and behaviors, and the vm_file field to specify which file is being mapped by the area, if any. A VMA that does not map a file is anonymous. Each memory segment above (e.g., heap, stack) corresponds to a single VMA, with the exception of the memory mapping segment. This is not a requirement, though it is usual in x86 machines. VMAs do not care which segment they are in.
结构体 vm_area_struct (VMA)表示一段连续的虚拟地址,VMA地址间不会相互重叠。VMA记录了虚拟地址段的开始地址和结束地址,访问权限和行为标记,如果有文件映射到该段,那么vm_file字段就指向被映射的文件。没有文件映射的VMA是匿名VMA。从上图可以看到,Text段和BSS段有文件映射,其VMA不是匿名的。Data段,Heap段和Stack段没有文件映射,其VMA是匿名的。每个虚地址段对应一个VMA,但Memory Mapping段例外。
A program’s VMAs are stored in its memory descriptor both as a linked list in the mmap field, ordered by starting virtual address, and as a red-black tree rooted at the mm_rb field. The red-black tree allows the kernel to search quickly for the memory area covering a given virtual address. When you read file /proc/pid_of_process/maps, the kernel is simply going through the linked list of VMAs for the process and printing each one.
mm_struct结构体的mmap字段指向进程VMA组成的链表,以VMA起始地址做升序排列。同时它的 mm_rb 字段指向VMA组成的一棵红黑树,红黑树使内核能够迅速找到包含某虚地址的VMA。当你查看进程文件 /proc/pid/maps 时,内核只是遍历VMA链表并依次输出。
In Windows, the EPROCESS block is roughly a mix of task_struct and mm_struct. The Windows analog to a VMA is the Virtual Address Descriptor, or VAD; they are stored in an AVL tree. You know what the funniest thing about Windows and Linux is? It’s the little differences.
Windows系统中,EPROCESS 结构体基本上是 task_struct 和 mm_struct 的大杂烩。VMA在Windows中的等价物是虚拟地址描述符(VAD),以AVL树存储。知道Windows和Linux最有趣的事情么?是它们之间的一点点小差别。
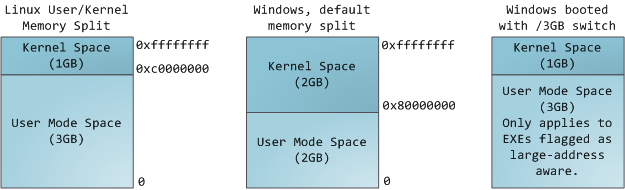
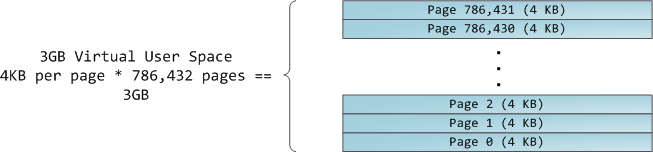
The 4GB virtual address space is divided into pages. x86 processors in 32-bit mode support page sizes of 4KB, 2MB, and 4MB. Both Linux and Windows map the user portion of the virtual address space using 4KB pages. Bytes 0-4095 fall in page 0, bytes 4096-8191 fall in page 1, and so on. The size of a VMA must be a multiple of page size. Here’s 3GB of user space in 4KB pages:
内核把4GB虚地址空间分割为页,或逻辑页,32位模式的x86处理器支持4KB,2MB和4MB的页大小。Windows和Linux都使用4KB的页大小。VMA描述的虚地址范围包含若干个page。下图显示了3G用户空间的page:
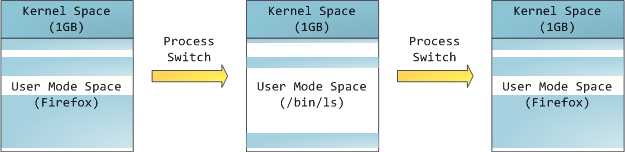
The processor consults page tables to translate a virtual address into a physical memory address. Each process has its own set of page tables; whenever a process switch occurs, page tables for user space are switched as well. Linux stores a pointer to a process’ page tables in the pgd field of the memory descriptor. To each virtual page there corresponds one page table entry (PTE) in the page tables, which in regular x86 paging is a simple 4-byte record shown below:
处理器访问页表把虚地址转换到物理地址,每个进程有自己的页表。当进程切换时,用户空间的页表也随之切换。Linux把页表地址存储在 mm_struct 结构体内名为 pgd 的指针内。页表内每个页表项(PTE)记录一个逻辑页。对于x86处理器,页表项大小为4B:
Linux has functions to
read and
set each flag in a PTE. Bit P tells the processor whether the virtual page is
present in physical memory. If clear (equal to 0), accessing the page triggers a page fault. Keep in mind that when this bit is zero,
the kernel can do whatever it pleases with the remaining fields. The R/W flag stands for read/write; if clear, the page is read-only. Flag U/S stands for user/supervisor; if clear, then the page can only be accessed by the kernel. These flags are used to implement the read-only memory and protected kernel space we saw before.
Bits D and A are for
dirty and
accessed. A dirty page has had a write, while an accessed page has had a write or read. Both flags are sticky: the processor only sets them, they must be cleared by the kernel. Finally, the PTE stores the starting physical address that corresponds to this page, aligned to 4KB. This naive-looking field is the source of some pain, for it limits addressable physical memory to
4 GB. The other PTE fields are for another day, as is Physical Address Extension.
A virtual page is the unit of memory protection because all of its bytes share the U/S and R/W flags. However, the same physical memory could be mapped by different pages, possibly with different protection flags. Notice that execute permissions are nowhere to be seen in the PTE. This is why classic x86 paging allows code on the stack to be executed, making it easier to exploit stack buffer overflows (it’s still possible to exploit non-executable stacks using
return-to-libc and other techniques). This lack of a PTE no-execute flag illustrates a broader fact: permission flags in a VMA may or may not translate cleanly into hardware protection. The kernel does what it can, but ultimately the architecture limits what is possible.
Virtual memory doesn’t store anything, it simply
maps a program’s address space onto the underlying physical memory, which is accessed by the processor as a large block called the
physical address space. While memory operations on the bus are
somewhat involved, we can ignore that here and assume that physical addresses range from zero to the top of available memory in one-byte increments. This physical address space is broken down by the kernel into
page frames. The processor doesn’t know or care about frames, yet they are crucial to the kernel because
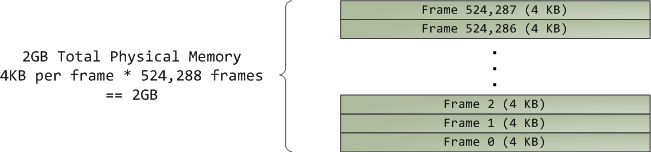
the page frame is the unit of physical memory management. Both Linux and Windows use 4KB page frames in 32-bit mode; here is an example of a machine with 2GB of RAM:
In Linux each page frame is tracked by a descriptor and several flags. Together these descriptors track the entire physical memory in the computer; the precise state of each page frame is always known. Physical memory is managed with the buddy memory allocation technique, hence a page frame is free if it’s available for allocation via the buddy system. An allocated page frame might be anonymous, holding program data, or it might be in the page cache, holding data stored in a file or block device. There are other exotic page frame uses, but leave them alone for now. Windows has an analogous Page Frame Number (PFN) database to track physical memory.
在Linux系统,页帧由一个描述符和一组标记位来跟踪。描述符精确地记录了物理内存的状况。所有这些描述符一起追踪了整个物理内存的使用状况。管理物理内存时使用了buddy memory allocation技术。已分配的页帧可能是匿名的,保存了程序数据,也可能用作page cache,保存文件或者块设备的数据。还有其他一些很奇特的页帧使用方式,不过现在不用去管。Windows也有类似的页帧号(PFN)来追踪物理内存。
Let’s put together virtual memory areas, page table entries and page frames to understand how this all works. Below is an example of a user heap:
现在,让我们把虚地址段(VMA),页表项和页帧放在一起,来理解虚拟内存是如何工作的。下面是一个用户空间堆的例子:
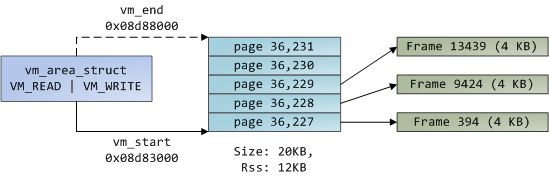
Blue rectangles represent pages in the VMA range, while arrows represent page table entries mapping pages onto page frames. Some virtual pages lack arrows; this means their corresponding PTEs have the Present flag clear. This could be because the pages have never been touched or because their contents have been swapped out. In either case access to these pages will lead to page faults, even though they are within the VMA. It may seem strange for the VMA and the page tables to disagree, yet this often happens.
最左边是堆对应的VMA,中间大的蓝色方框是进程的页表,包含很多页表项。最右边的绿色方框表示物理页帧。它们之间的箭头表示逻辑页到物理页帧的映射关系。还有一些逻辑页没有箭头,这表示页表项的P位为0,有可能因为该页从来没有被访问过,或者物理页帧被换出到swap。此时访问该逻辑页将导致page fault(缺页故障).
A VMA is like a contract between your program and the kernel. You ask for something to be done (memory allocated, a file mapped, etc.), the kernel says “sure”, and it creates or updates the appropriate VMA. But it does not actually honor the request right away, it waits until a page fault happens to do real work. The kernel is a lazy, deceitful sack of scum; this is the fundamental principle of virtual memory. It applies in most situations, some familiar and some surprising, but the rule is that VMAs record what has been agreed upon, while PTEs reflect what has actually been done by the lazy kernel. These two data structures together manage a program’s memory; both play a role in resolving page faults, freeing memory, swapping memory out, and so on. Let’s take the simple case of memory allocation:
VMA就好比你和内核间的契约,你请求完成一些操作(内存分配,文件映射,等等),内核说“没问题”,然后创建或者更新相应的VMA,但它并没有把你的请求放在心上,而是一直等到缺页故障发生时才去执行请求。内核就好像是一个又懒又诡计多端的人渣。以上就是虚拟内存的基本原理。它适用于大多数场景,有些你熟悉,有些令你吃惊,但规则是VMA记录程序和内核达成的协议,而页表反映懒惰的内核真正做了哪些。这两个数据结构共同管理着进程的内存,共同解决缺页故障,释放内存,换入换出内存等操作。让我们来看一个内存分配的简单场景:
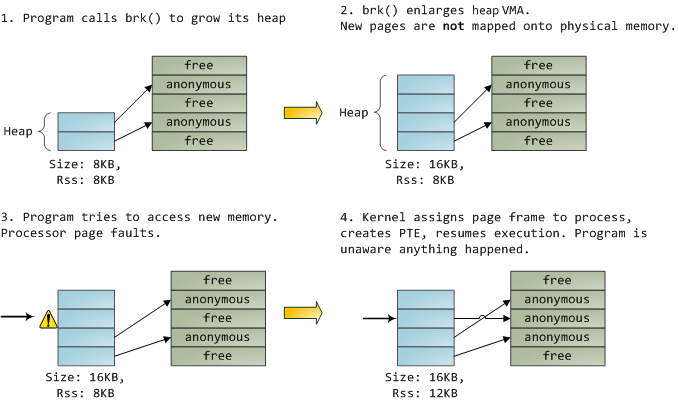
When the program asks for more memory via the brk() system call, the kernel simply updates the heap VMA and calls it good. No page frames are actually allocated at this point and the new pages are not present in physical memory. Once the program tries to access the pages, the processor page faults and do_page_fault() is called. It searches for the VMA covering the faulted virtual address using find_vma(). If found, the permissions on the VMA are also checked against the attempted access (read or write). If there’s no suitable VMA, no contract covers the attempted memory access and the process is punished by Segmentation Fault.
当程序执行 brk() 系统调用请求更多内存,内核只是更新堆的VMA,并没有真的分配页帧。一旦程序试图访问新创建的逻辑页,处理器会报缺页故障,并执行 do_page_fault() 方法。该方法又调用 find_vma() 方法来找到逻辑地址所在的VMA,如果找到了,内核会对比VMA上的访问权限和要执行的操作(读或写)。如果没找到VMA,说明程序和内核没有达成该地址的契约,那么进程会受到段错误的惩罚。
When a VMA is found the kernel must handle the fault by looking at the PTE contents and the type of VMA. In our case, the PTE shows the page is not present. In fact, our PTE is completely blank (all zeros), which in Linux means the virtual page has never been mapped. Since this is an anonymous VMA, we have a purely RAM affair that must be handled by do_anonymous_page(), which allocates a page frame and makes a PTE to map the faulted virtual page onto the freshly allocated frame.
找到VMA后,内核会继续找到逻辑地址所在的页表项,在本例,页表项是完全空白的,表明该逻辑页还没有映射到物理页帧。因为要访问的内存段是匿名的,内核必须调用 do_anonymous_page() 方法,分配物理页帧,并把它映射到出错的逻辑页,记录在页表项里。
Things could have been different. The PTE for a swapped out page, for example, has 0 in the Present flag but is not blank. Instead, it stores the swap location holding the page contents, which must be read from disk and loaded into a page frame by do_swap_page() in what is called a major fault.
对于交换出去的页,其页表项的P标记位为0,地址字段则指向存放页内容的swap位置。访问这样的页会引发 major fault ,通过调用 do_swap_page() 从磁盘读取内容,保存在物理页帧。而应用程序对此一无所知。
This concludes the first half of our tour through the kernel’s user memory management. In the next post, we’ll throw files into the mix to build a complete picture of memory fundamentals, including consequences for performance.
到这里我们已经走过了内核内存管理之旅的前半部分旅程,在下一篇文章中,我要把文件也加进来,构建一副完整的内存管理画面,以及对性能的后果。